KAG vs RAG
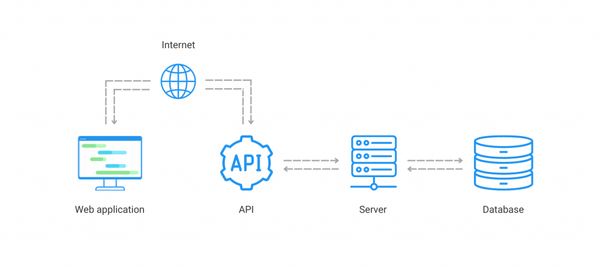
RAG - pour ceux qui ne le savent pas encore - signifie Retrieval Augmented Generation : l'idée du système est que l'utilisateur donne des documents à un LLM et celui-ci répond à ses questions en se basant sur le contenu des documents - et uniquement ce contenu, en limitant les hallucinations ou les réponses à côté de la plaque.
Le RAG fait fureur en ce moment (on pourrait dire que les gens sont enRAGés, mais non), mais les internets bruissent depuis peu de quelque chose de peut-être plus intéressant : la KAG, ou Knowledge Augmented Generation.
Si nous simplifions le RAG, le processus est le suivant :
- Extraction du contenu des fichiers
- Découpage du contenu du fichiers en chunks (morceaux) et encodage avec un LLM spécifique
- Encodage de la question posée au RAG avec le même LLM spécifique
- Récupération des chunks de documents les plus pertinents (=qui ressemblent le plus à la question posée)
- Transmission à un autre LLM des chunks : à partir de ces chunks, le LLM crée la réponse.
Le but du RAG : filtrer toutes les informations des documents pour ne récupérer que les éléments les plus pertinents. Mais le fait-il bien ?
Le problème est que l'encodage est une sorte de boîte noire, dont on ne mesure pas trop la qualité. Elles dépend des chunks fournis (choisis arbitrairement) et la récupération des chunks est simplement basée sur une question de distance (ce qui signifie : se ressemblent ils ? sont-ils éloignés l'un de l'autre ?).
De nombreuses recherches sont actuellement menées dans ce domaine afin d'améliorer les résultats. L'une des solutions pourrait être l'idée de KAG : Knowledge Augmented Generation.
Dans le KAG, nous ne comparons pas simplement les choses sur la base de leur ressemblance, mais l'encodage est remplacé par une phase où un LLM crée une représentation graphique des données : il crée des relations entre les parties des documents fournis. Ainsi - théoriquement - il peut conserver un meilleur contexte, ce qui signifie qu'il peut fournir de meilleurs résultats en bout de chaîne.
Bon, tout ça est très expérimental, mais il existe des articles sur des initiatives menées ici ou là :
https://pub.towardsai.net/kag-graph-multimodal-rag-llm-agents-powerful-ai-reasoning-b3da38d31358
https://towardsdatascience.com/enterprise-ready-knowledge-graphs-96028d863e8c
Notamment le projet OpenSPG, développé par Ant Group :
Ca a l'air d'être une façon intéressante de traiter les documents et d'en extraire des informations - quelle époque passionnante pour travailler sur l'IA !